![]()








HOME > ActionScript > スライドアルゴリズム > データの準備

定義と仕様
色々と試して最終的に結構割り切ったアルゴリズムになっています。
最適な仕様は他にあると思いますので、私の公開するアルゴリズムは一つの方法論だと言う程度に解釈して下さい。
ではまず作成を進めていく上での便宜上の定義と主な仕様を決めておきます。
定義
ここで言う「定義」はこれからの文章などに出てくる、用語や概念などの認識をすり合わせておくための統一事項として書き留めておくものです。現段階でとりあえず必要な最低限の項目だけ提示しておいて、おいおい追加していきます。
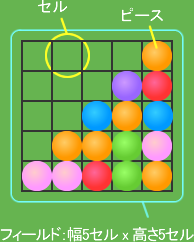
| 用語 | ピース | 画面上に並べるブロックをここではピースと呼びます。 |
|---|---|---|
| フィールド | ピースを配置するステージ上の領域の事。 | |
| セル | フィールドをグリッド分けして出来るマスの事をここではセルと呼びます。基本的にセルとピースは縦横の幅を同じにします。 また、このセルは描画される要素ではありません。 |
仕様
次に「仕様」としてプログラミングの工程に関わる大まかな事項を書き留めておきます。
後は必要に応じて追記して行きます。
| 基本仕様 | 仕様 ピースは色い違いの円形を4パターン(4色)。 |
|---|---|
| ピースのサイズは縦横共に40 pix(セルも同サイズ) | |
| ピースの並びはフィールドに縦横5 x 5で並べる(変更あり)。 | |
| 操作系 | マウス操作のみ |
ピースについて
フィールドに配置するピースはFlash CS5を使用して作成したMCを使用します。
ダウンロードファイルに含まれているflaファイルが使えない様な場合は以下の内容のMCを作成したflaファイルを用意して下さい。
まず名前とクラス名を「PieceMC」、基本クラスを「MovieClip」としたMCをライブラリに作成します。
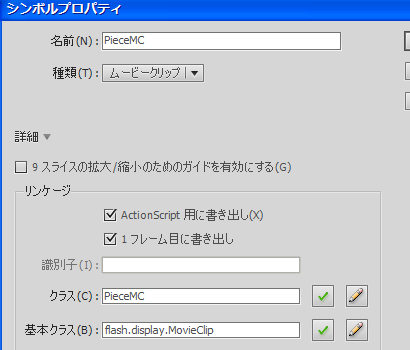
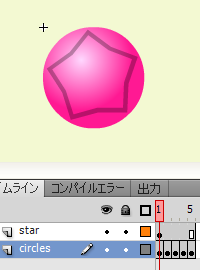
PieceMCの内容は、タイムラインの長さを4フレーム(それ以上でも大丈夫ですが4フレーム分しか使用されません)にして、各フレームに縦横40pxの大きさの適当な絵柄を柄違いで描いて下さい。単純な円形の色違いでOKです。描画した短形の配置は基準点が左上に来るように配置して下さい。
用意するMCはそれだけです。ステージに配置する必要もありません。後はflaファイルからドキュメントクラスになるMain.asを読み込むように設定して下さい。
ソースファイルについて
ダウンロードリンクにあるzipファイルの中にはドキュメントクラスとなるMain.asファイルの他に、CS5とCS4形式で保存したflaファイルが一つずつ入っています。これらのflaファイルはCS4とCS5のバージョン以外では開けません。中のフォルダ構成がそのままならflaファイルをFlash CS5もしくはCS4で開いてパブリッシュすれば動作するはずですが、フォルダやファイルを個別に移動した場合はそれに合わせて適宜flaファイルの設定を変更して下さい。
- PiecesSlide.fla(CS5用)
- PiecesSlide_forCS4.fla (CS4用)
- src/Main.as
- bin/
基本的にはCS5用のファイルを使用する事が前提で進めますが、FlashCS4を使用している方はCS4用の方を使用して下さい。
ただしCS4用のflaファイルについてはFlash CS5でCS4用に保存したものですので動作確認はしておりません。開けなかったり使用できない場合があるかもしれませんが、その際はどうぞご容赦願います。
またファイルの設定などはWindows環境での作業を想定していますので、Flash CS5を使用していてもそのままの設定では使えない場合があります。適宜設定を変更するなどしてご使用願います。
flaファイルの設定などがわからない場合は公式リファレンスを参考にして下さい。申し訳ありませんがご質問等にはお答えできません。
データの管理
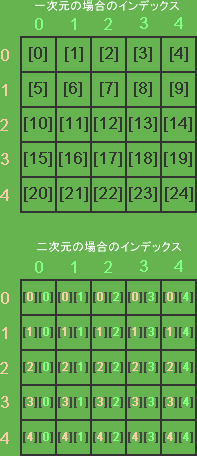
まずフィールドの状態(主に各セルに配置されているピースの絵柄)をデータとして管理するVector配列を用意します。テトリスでは二次元配列で扱いましたが、今回は一次元で扱います。なので配列の長さはフィールドにあるセルの数と同じになります。
private var piecesFieldData:Vector.<int>;
今回一次元配列でデータを扱う理由は、一次元でも手間はそれほどかわらないと言う事を理解してもらいたいという意図があります。
二次元の場合はフィールド上のセルの番地を配列のインデックスに対応させられるので、イメージとして解りやすいという利点がありますが、一次元でも基本的には同じ様な手順で要素を走査しますので慣れてしまうとこちらの方が色々と楽だったりするのでお得な気がします。
pieceFieldData配列の要素にはピースの絵柄を表すコードを入れていきます。これは絵柄の種類一つずつに1~4(4種類以上ならそれに合わせて増やす)の番号を割り当てて、どこのセルにあるピースが現在はどの絵柄なのかを表します。
Main.asファイルではピースを表すコードを定数で宣言していますが、まだ準備しただけでpiecesFieldData配列には何も処理をしない状態です。他にもフィールドのセルの並び数や総数などを定数で宣言してありますので確認してみてください。
一次元と二次元の比較
Array型の様な一般的な配列の処理では二次元よりも一次元で扱うほうが若干処理が早くなると言われています。ですが現在のCPUならどちらでもそれほどの差はでないなどという話も聞きましたので、ActionScript3.0で実際に単純な処理を作って時間を計ってみました。結果的には使っているマシンスペックや環境によって、一次元の方が速かったり二次元の方が速かったりで、劇的な差は観測できませんでした(私は2台のマシンで検証しました)。なのでホントにそんなに変わらないのかなという印象です。
下のプレビューを実行するとしばらく何も表示されませんが、内部で幾つかの配列の処理を一所懸命に繰り返しています。我慢強く待っていると実行に要した時間(単位1000ミリ秒)が処理結果として表示されます。
ただ、配列の要素に格納するデータ型や、要素に対して何を実行するかによっても大きく変わってくると考えられますので、私の検証結果だけで色々と断定することは控えます。
にしても意外だったのは密で高速な配列であるはずのVector配列が、マシンによっては二次元配列にしてしまうと通常のArray型配列よりも処理が遅くなるという点です。検証してみたところ、これは格納している要素が参照型だった場合、Array型とそれほど変わらないような結果になる事がわかりました。
しかしながらプリミティブな値を扱う場合においては、Vector配列はArray配列よりも圧倒的に高速でした(配列長固定ならさらに高速)。
隣接リストテーブル
一次元配列でのデータ探索のために、フィールドのセル同士の関連性を表す隣接リストのテーブルを作ります。隣接リストとは、もともとはグラフを表す為の表現方法らしいのですが、プログラムではデータ構造として幅広く応用できるデータの表現方法です。
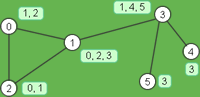
基本的には一つのノードに対して一つの辺で繋がっているその他のノードについての情報をリスト化したデータ構造ですが、繋がりの情報だけではなく関連性などの情報も持たせたり、また繋がりに「向き」を持たせたりする事もあります。向きがあると言うのは、0番のノードから1番のノードへは行けるけれど、1番から0番へは行けないと言う様な方向性の事で、例えばこれを迷路のマップデータで「一方通行の扉」などに応用したりする事も出来ます。
今回はこの隣接リストを用いてフィールド上のセル同士の関連性をテーブル化してあらかじめ配列データとして作成しておきます。こうする事で、例えばどこかのセルの上にあたるセルのインデックスを探索する時に配列の走査処理を簡略化できます。
とは言え、実のところ今回のプログラム程度の探索規模ではあまり恩恵はなかったりします。今回のところはこういった手法もあると言う程度の出番です。
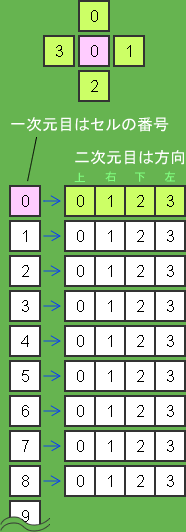
隣接テーブルの形式
隣接テーブルもVector配列で用意します。
private var adjacencyTable:Vector.<Vector.<int>>;
配列の長さはフィールドを管理する配列の長さと同じ長さになります。各要素にはさらにVector配列を入れて二次元配列とします。
二次元目の配列の長さは4で固定で、これは一つのセルから見た4方向に対応させます。
インデックス0を上の情報として、1が右、2が下、3が左と、時計回りで順に収めます。
実際にデータを探索する際には以下の様に指定します。
例として「インデックス12番のセルの下にあるセルのインデックス番号」を取得します。
adjacencyTable[12][2];
二次元目のインデックス指定をわかりやすくするために、定数を用意します。
private const TOP:uint = 0; private const RIGHT:uint = 1; private const BOTTOM:uint = 2; private const LEFT:uint = 3;
すると先の例のインデックスの取得は次の様になります。
adjacencyTable[12][BOTTOM];
実際には一つだけを取得して終わりと言う状況は殆どありませんので、大抵は一つを見つける為にループ処理の中で上の様な指定の仕方で配列を走査、探索していく感じです。
ちなみにこの隣接リストテーブルの配列も二次元ではなく一次元で再現可能です。その場合は要素4つ毎を一つのセルの情報として扱えば同じ様に使用できます。
じゃあなんでしないんだよと言いますと、忘れてました。。。
番兵
さて、フィールドのセルの中には4方向全てにセルが隣接していないセルもあります。一番外側のセルがそうです。例えば一番右端に並ぶセルの右側にはセルは存在しません(配列としては連続しています)。 この場合はここには「何もない」、または「壁」という事を示すコードを入れておきます。 いわゆる「番兵(Sentinel)」です。これはとりあえず999を使用しておきます。基本的にはセルの番号と重複しなければなんでも良いです(つまり配列長以上の値)。これも定数で用意します。
private const WALL:uint = 999;
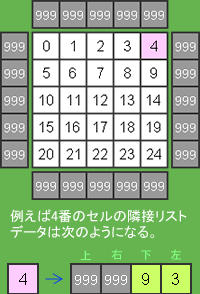
例えばWALLの値を評価しながら、以下の様にループ処理を実行します。
while (adjacencyTable[index][RIGHT] != WALL) index++;
上の処理は右に向かって壁にぶつかるまで、セルのインデックスをインクリメントして行きます。これで特定のセルが存在する行の一番右端のセルのインデックスを取得できます。
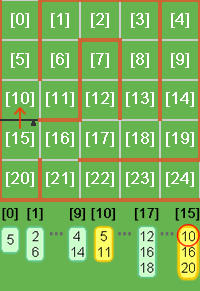
隣接リストテーブルを作成
隣接リストテーブルを作成するのはmakeAdjacencyTable()関数です(Main.asファイル64行目)。関数の内容は特に説明しませんが、フィールドに並べるセルの数が変わっても、ちゃんと外周のセルなどのデータも正しく作成されるようになっています。
関数の実行(Main.asファイル52行目)後に作成した隣接リストテーブルの状態を出力していますので(Main.asファイル55行目)、Flashのプレビューウィンドウで確認してみてください。
値の状態と上の画像を比較してみるとわかりやすいはずです。
![]()
![]()